서론
요즘은 잠잠하지만 국가별 코로나19 확진자 수에 대해서 한동안 말이 많았다.
특히 중국 등 몇몇 국가들에 대해서 확진자 수를 조작, 은폐하는 것 아니냐는 의심의 눈초리들이 있었다.
우리가 알 수 있는 것은 공식적으로 발표된 통계 자료뿐이기 때문에 무엇이 진실인지는 알기 어렵다.
그런데 "벤포드 법칙"에 따르면 숫자 데이터들의 앞자리가 무엇인지를 분석하여 부정이나 조작을 탐지할 수 있다고 한다.
상당히 흥미로운 내용인 데, "벤포드 법칙"을 간편하게 적용해볼 수 있는 파이썬 라이브러리가 있다는 것을 알게 되었다.
코로나19 확진자 통계 자료에 이를 적용해보자.
본론
벤포드 법칙 소개
1. 벤포드 법칙이란 무엇인가?
벤포드 법칙은 정말 단순하다.
현실 세계에서는 수많은 수치 데이터들이 존재하는데, 그 데이터들의 앞자리 숫자를 분석해보면 작은 숫자가 나올 확률이 큰 숫자가 나올 확률보다 크다는 것이다.
그냥 직관적으로 생각해보면 1부터 9까지의 숫자가 비슷한 확률로 등장할 것 같지만, 사실은 1이 가장 많이 등장한다고 한다.
예를 들어 첫번째 자리를 분석해 보면, 1이 30.1%, 2가 17.6%, 3이 12.5%이고, 9는 4.6%밖에 나오지 않는다고 한다.
물리학자인 프랭크 벤포드라는 분이 이에 대 논문을 발표해서 벤포드 법칙이라고 불리게 되었다고 한다.
자세한 내용은 벤포드 법칙에 관한 위키백과 문서(국문, 영문)를 참조하기 바란다.
2. 믿을 만한 법칙인가?
필자가 벤포드 법칙에 대해 알고 호기심이 생겨서 여기저기 적용을 해보았는데, 솔직히 말해서 벤포드 법칙에서 얘기하는 비율에 모든 데이터가 딱 들어 맞지는 않는다.
그러나 대부분의 데이터에서 작은 숫자가 더 많이 나오는 경향성을 보이는 것은 사실이었다.
따라서 벤포드 법칙에서 말하는 비율에 정확히 맞지 않는다고 해서 반드시 어떠한 조작이 있을 거라고 단정할 수는 없지만, 이상징후를 포착하는 단서로서의 역할은 충분히 할 수 있다고 생각한다.
실제로도 벤포드 법칙을 적용하여 회계 부정을 밝혀낸 사례가 있다는 것을 알고 놀랐다.
한때 뉴스에 많이 등장했던 엔론 사태가 바로 그 사례인데, 미국의 수학자인 마크 니크리니라는 분이 엔론의 회계장부를 분석한 결과 벤포드 법칙과 달리 첫 자리에 7, 8, 9가 많다는 것을 발견하고 이를 보고하여 엔론의 회계 부정이 밝혀지게 되었다고 한다.
분석 방법 소개 및 분석 결과
1. 무엇을 분석하나?
데이터 분석을 하려다 보면, 최종 분석보다도 필요한 데이터를 찾고 분석이 가능하도록 전처리하는 데에 시간이 더 드는 것 같다.
이리저리 찾아본 결과 아래 데이터를 찾았다.
국가별, 일자별 코로나 신규 확진, 누적 확진 수치 및 사망자 숫자 데이터인데, "the Humanitarian Data Exchange"에 올라와 있는 것이다.
총 200여개국의 데이터가 모두 들어 있는데, 여기에 모두 소개할 수는 없으니 확진자 수가 가장 많은 국가들과, 우리가 관심이 많은 우리나라, 중국, 일본의 데이터에도 적용해보자.
2. 어떻게 분석하나?
벤포드 법칙은 그 내용이 무척 단순하기 때문에 파이썬 문법과 판다스 등 데이터 분석 관련 라이브러리의 사용 법을 어느 정도 익힌 사람이라면 쉽게 접근해 볼 수 있는 주제이다.
그렇지만 "do not reinvent the wheel"이라는 말이 있지 않은가?
여기에서는 이미 벤포드 분석을 편하게 할 수 있도록 만들어진 라이브러리(benfordslaw)를 활용한다.
원본 CSV 데이터에서 국가별 데이터를 뽑아내는 일은 pandas 라이브러리를 활용한다.
3. 스크립트 소개
우선 원본 csv 파일을 불러오자.
import pandas as pd
df = pd.read_csv('WHO-COVID-19-global-data.csv')
그 다음으로는, 확진자 수가 많은 국가를 분석 대상으로 하기로 했으므로, 분석 대상 국가를 추려준다.
num_of_cases = df.groupby('Country')['Cumulative_cases'].max()
# 국가별로 그룹을 지은 뒤에, 그룹별로 '누적 확진자수' 열의 최대값을 가져온다.
countrys_top = num_of_cases.nlargest(10).index
# 위에서 가져온 자료에서 상위 10개를 추출한 다음에 행이름(index), 즉 국가명만 가져온다.
이제는 벤포드 법칙을 적용할 차례이다.
벤포드법칙 라이브러리를 임포트한 뒤에, 국가별로 분석해주는 함수를 정의한다.
from benfordslaw import benfordslaw
def benford(country, pos):
global df
# 앞서 정의한 df 변수를 함수 내에서 사용하기 위해 global 변수로 선언한다.
df_country = df[df.Country == country]
# df에서 분석 대상 국가의 데이터만 추출한다.
data = df_country['New_cases']
# 신규 확진자수를 data 변수로 지정한다.
bl = benfordslaw(alpha=0.05, method='ks', pos=pos, verbose=3)
# 벤포드 분석 인스턴스를 만든다. method의 경우 chi2, ks 등 여러 옵션이 있는데, chi2는 오류가 잦은 편이다.
results = bl.fit(data)
# 벤포드 분석 실시
bl.plot(title=country+', pos: '+str(pos))
# 차트로 출력(제목은 국가명과 분석 대상 자릿수로 설정)
그런 다음, 분석 대상 국가별로 위에서 정의한 함수를 실행한다.
for country in countrys_top:
benford(country, 1)
4. 분석 결과
함수를 실행하면 t-stat이나 p-value 등 통계 수치와 함께 이상수치 발견이 되었는지를 알려주는 메시지("anomaly detected!")가 나오는데, 그런 것들은 빼고 그래프만 보기로 하자.
※ 필자는 통계학적 지식이 전무한 관계로 그래프만 출력되도록 benfordslaw 스크립트의 일부를 수정했다. 위에 소개한 스크립트를 실행해보면 표에 위와 같은 통계 정보가 함께 출력될 것이다.
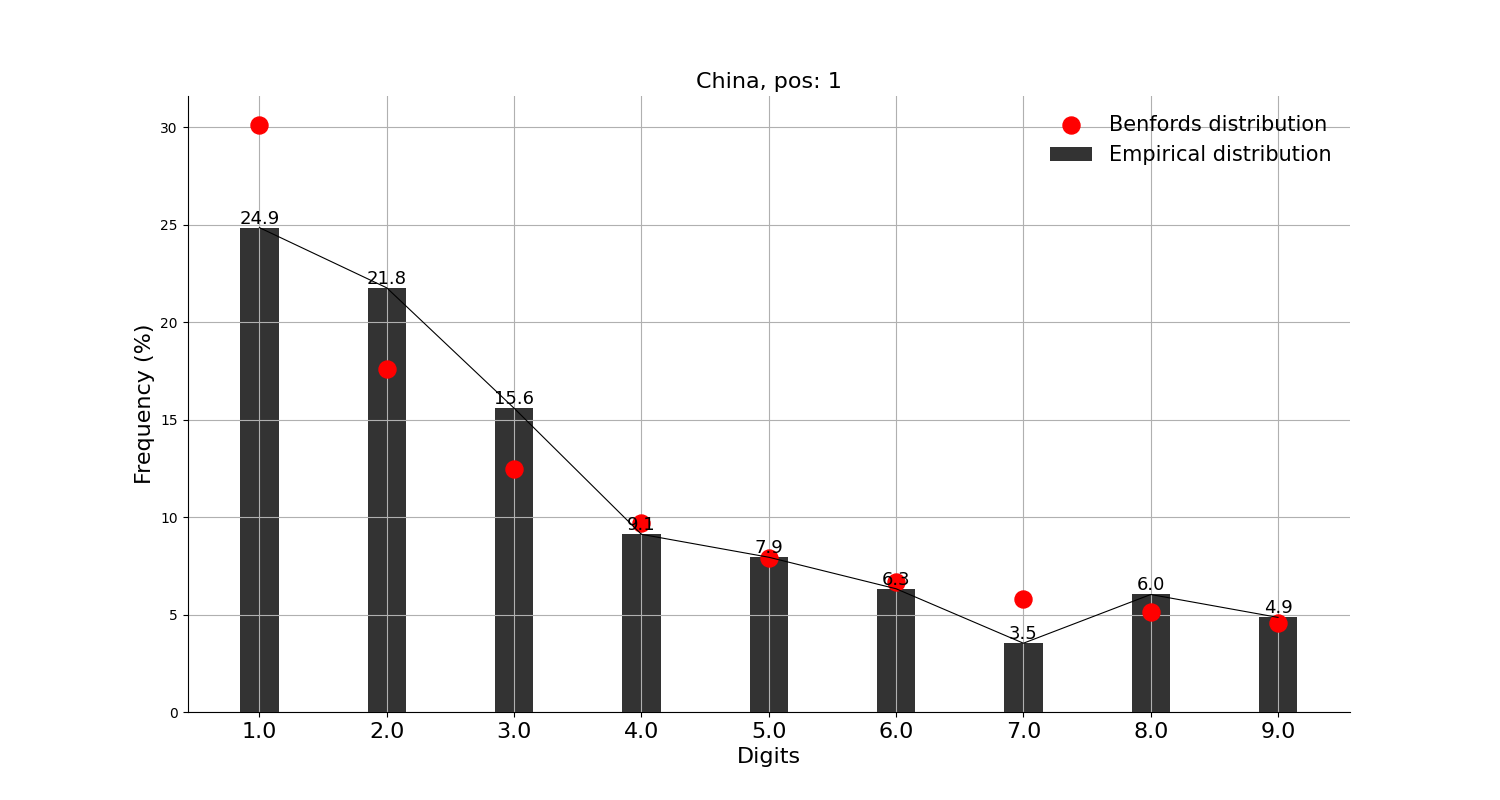
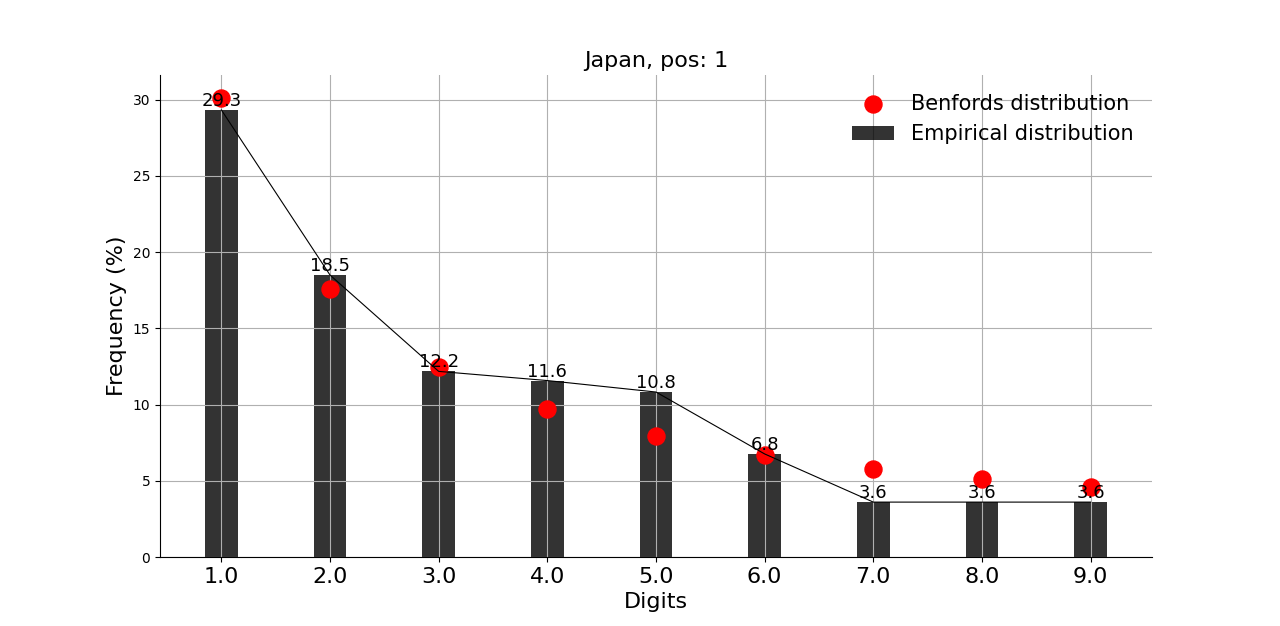
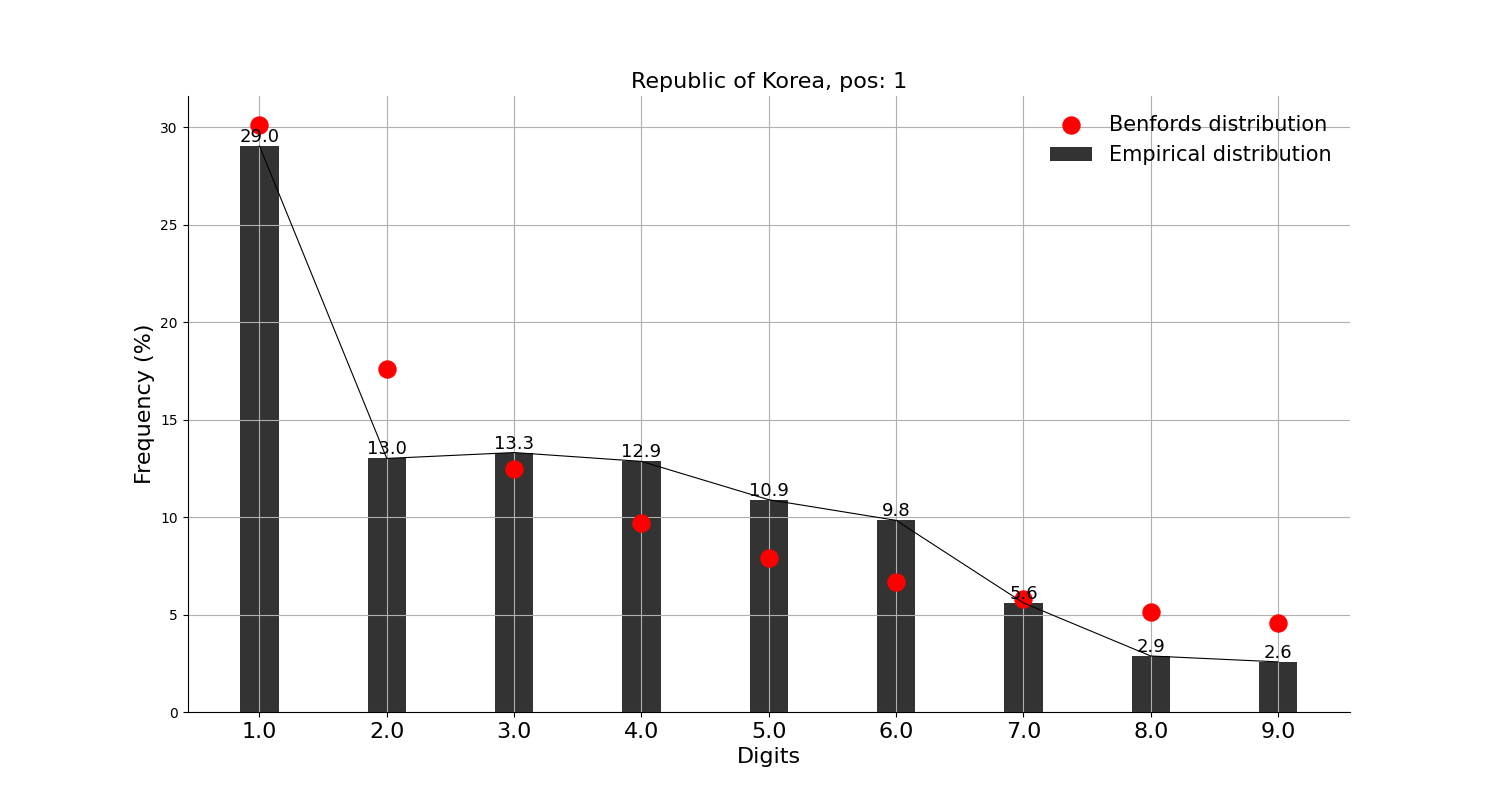
그래프의 빨간 점이 벤포드 법칙에서 말하는 비율이고, 검은 막대가 실제 데이터이다.
※ 앞서 언급했지만, 벤포드 법칙을 적용한 분석 결과 자체로는 어떠한 결론도 내릴 수가 없다. 재미로만 보자.
먼저, 확진자수 상위 10개국에 적용해본 결과,
미국, 인도, 브라질, 영국, 프랑스, 이란, 독일, 아르헨티나 등 8개국은 각각 정도의 차이는 조금 있으나 '대체로 작은 숫자가 큰 숫자보다 많다'고는 할 수 있을 것 같다.
반면, 러시아와 터키는 그렇다고 말하기 어려워 보인다.
이 중 러시아의 경우 최근 워싱턴포스트에서 통계 조작 의혹을 제기하였다는 점에서 흥미롭다.

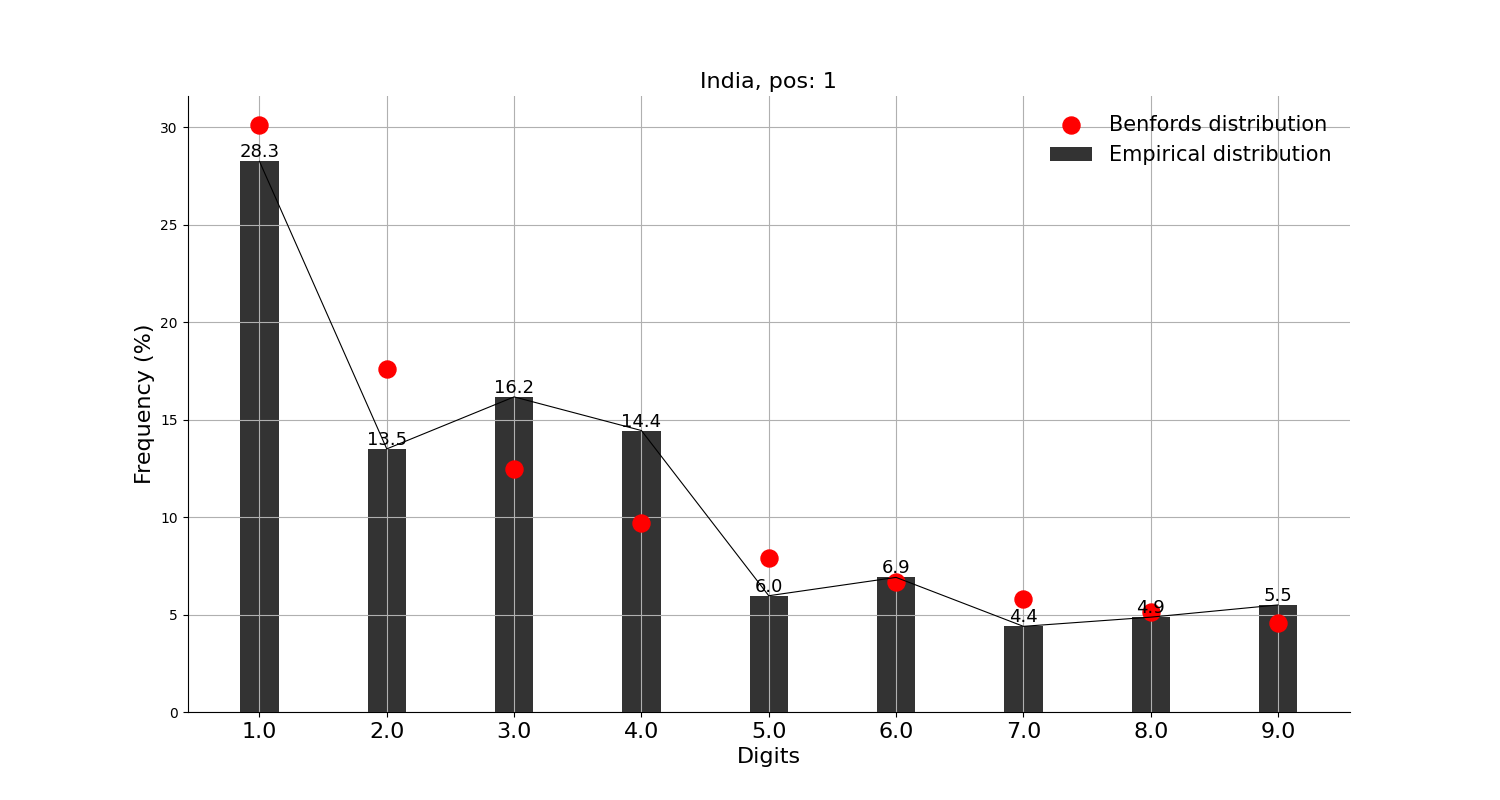
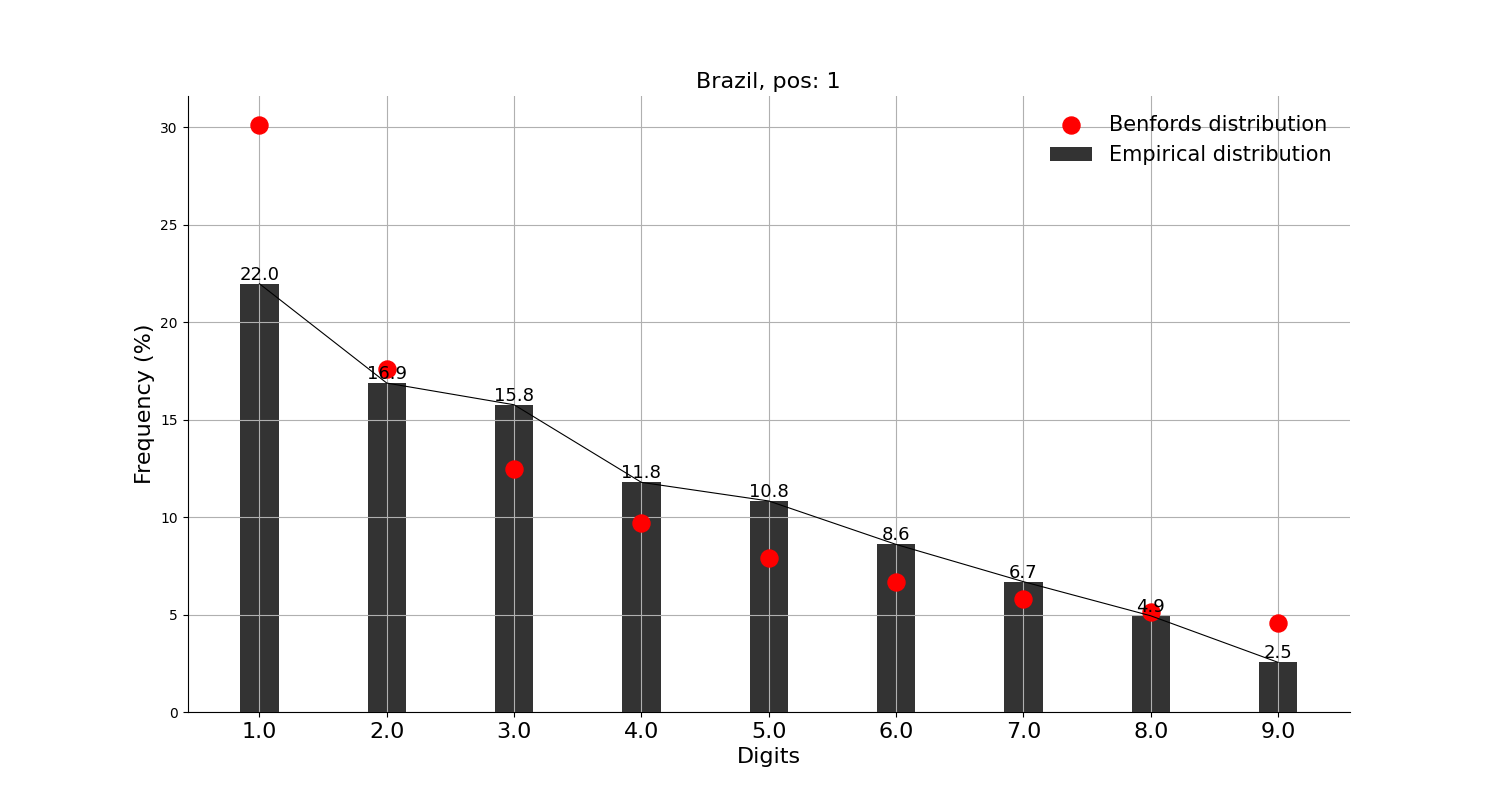
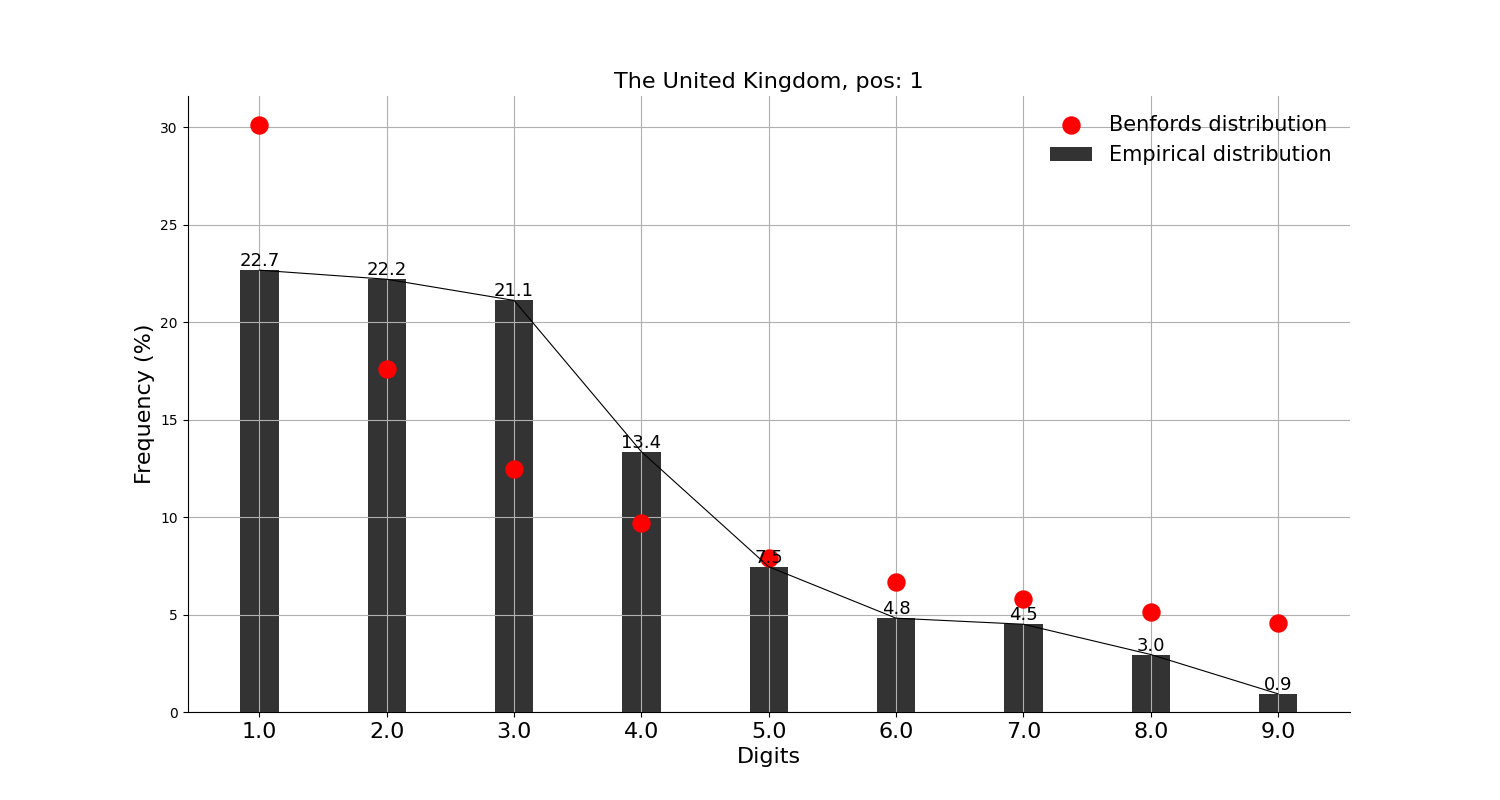
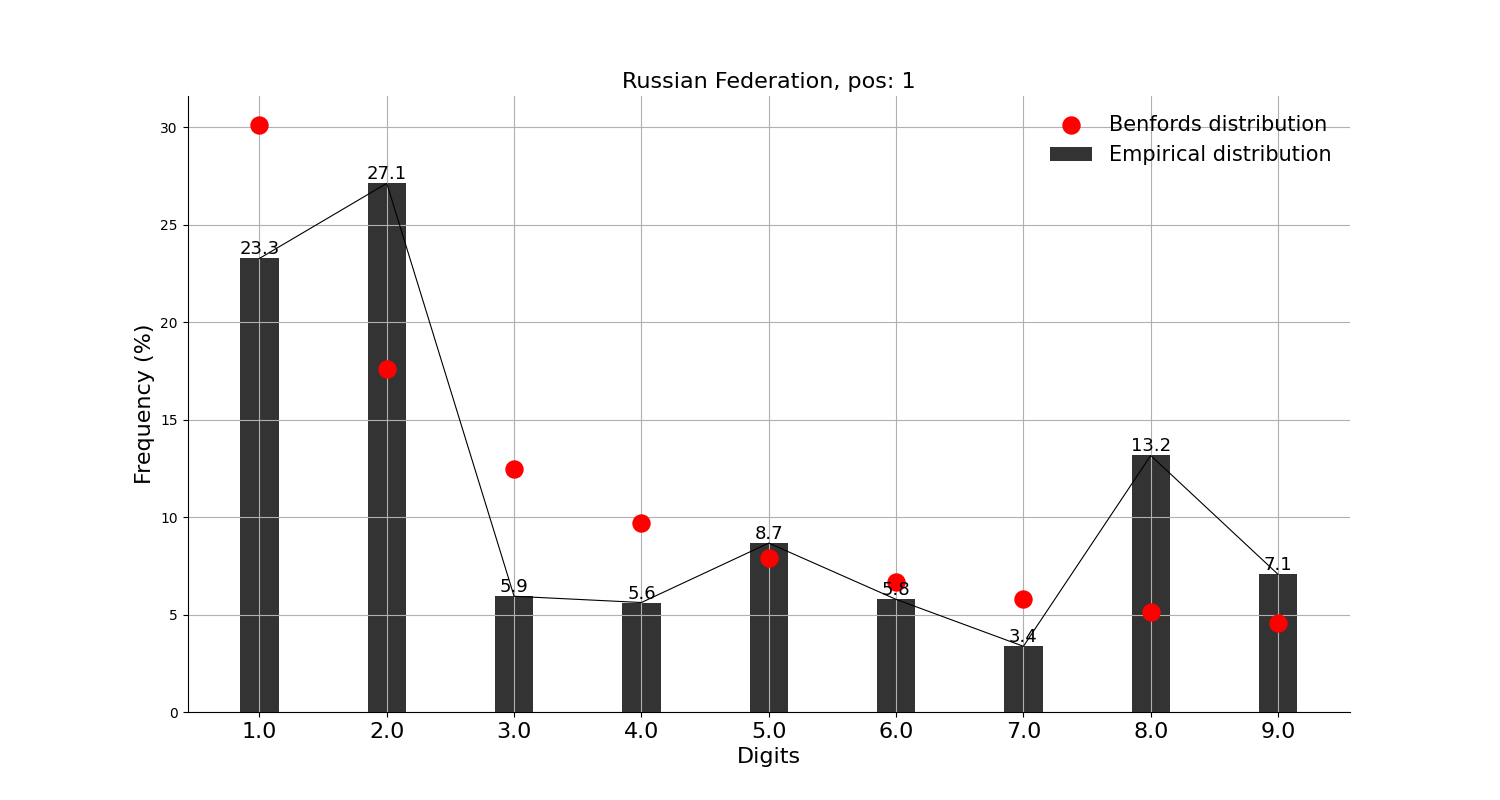
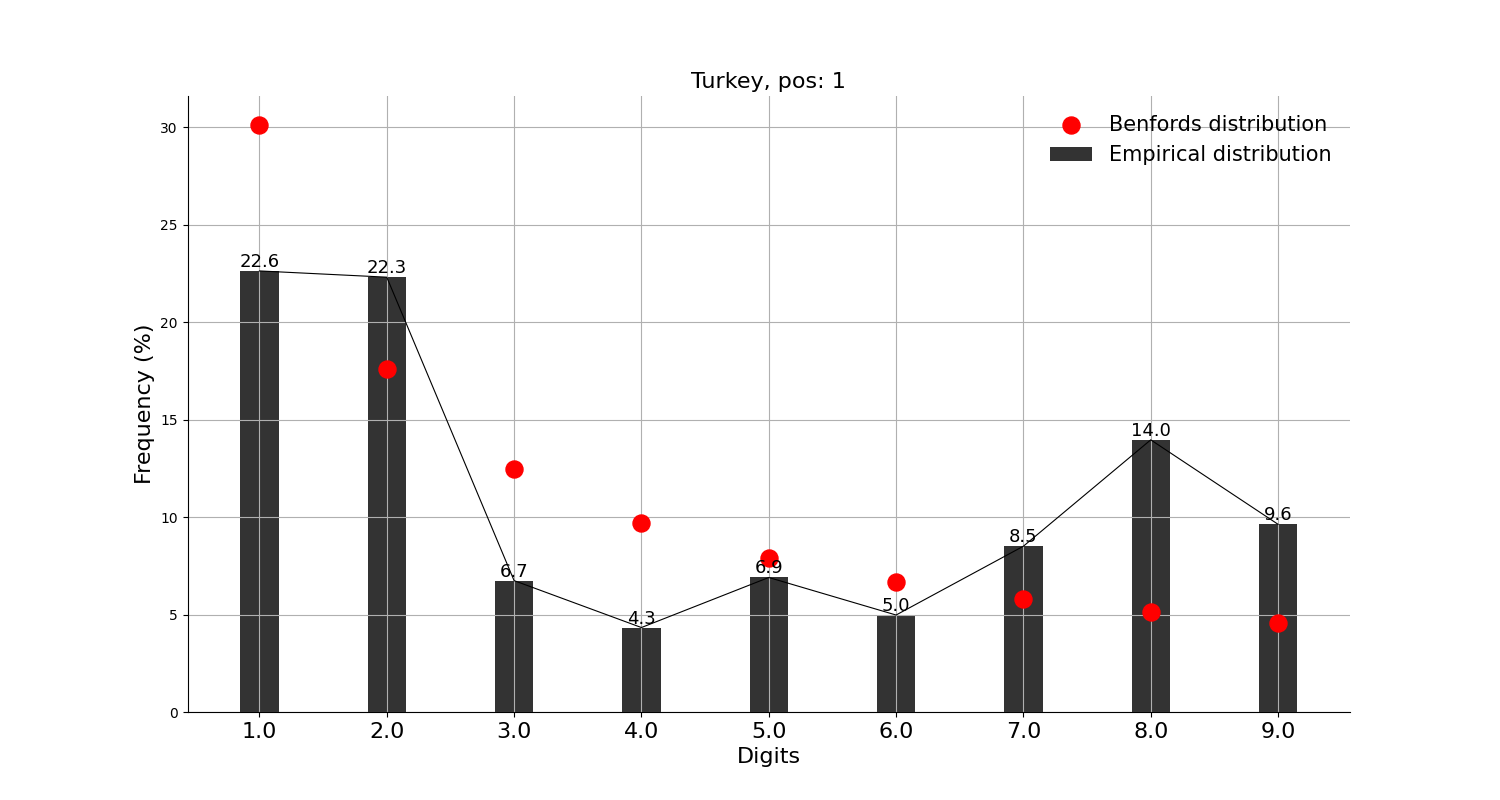
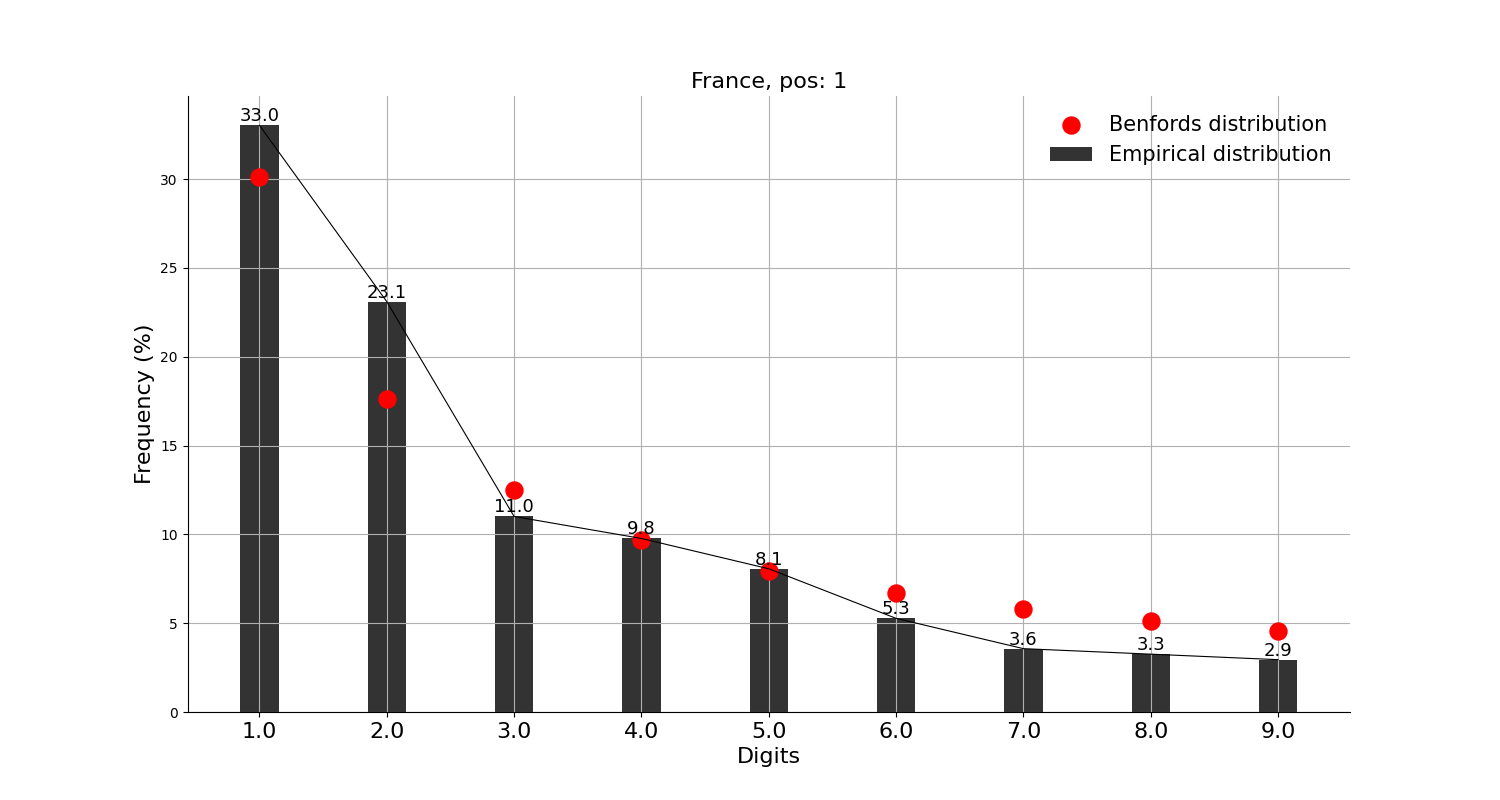
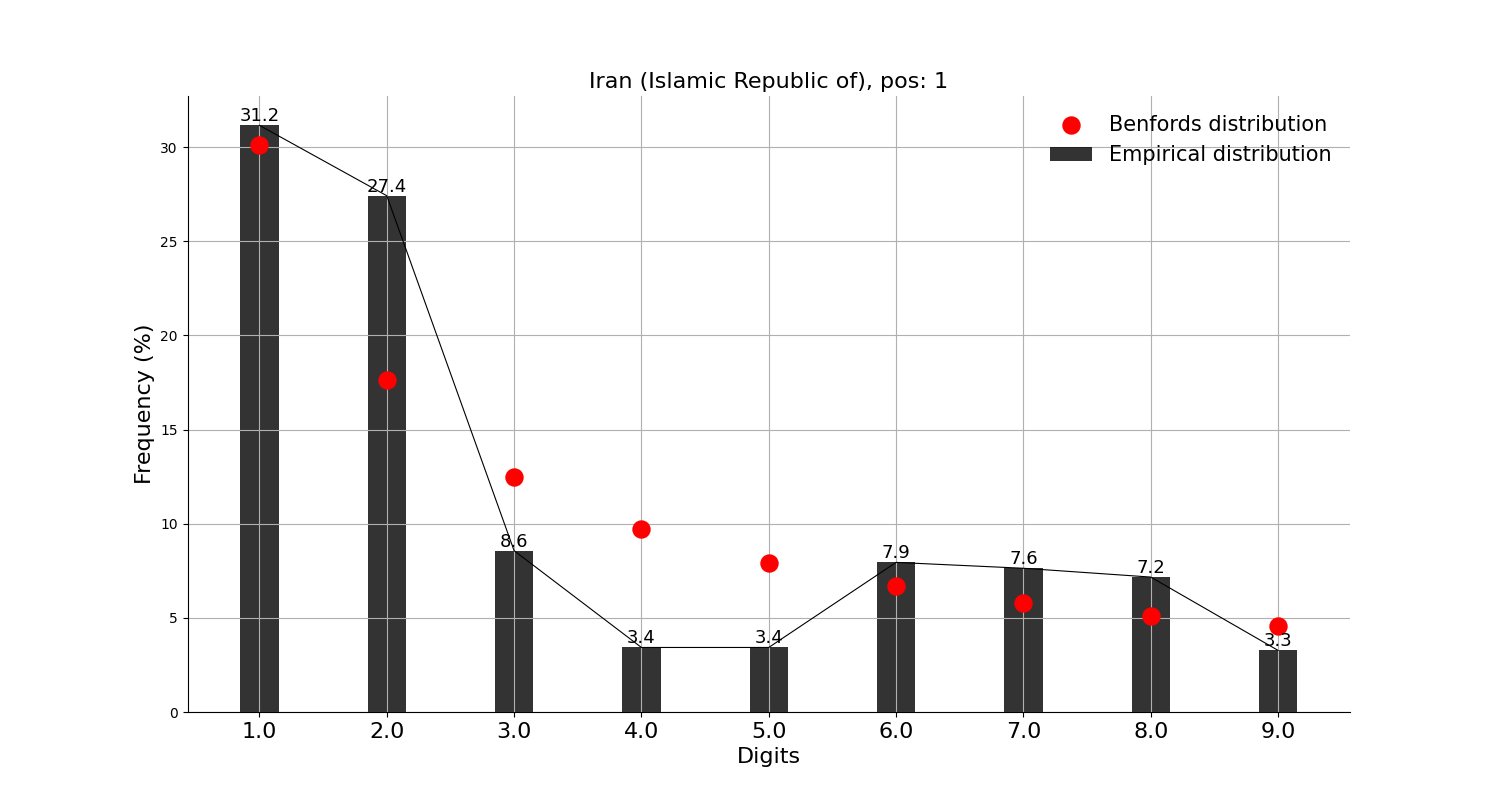
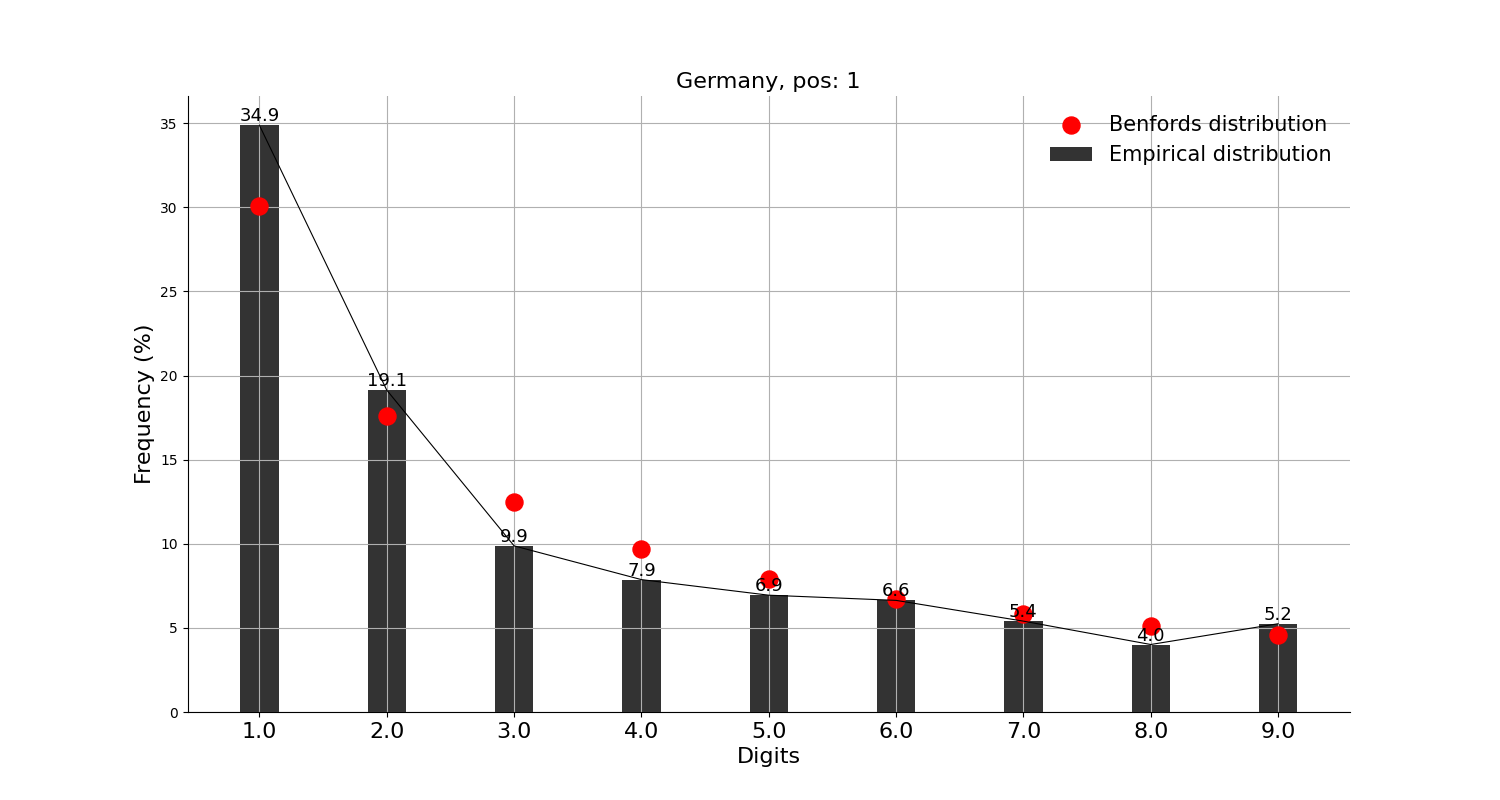
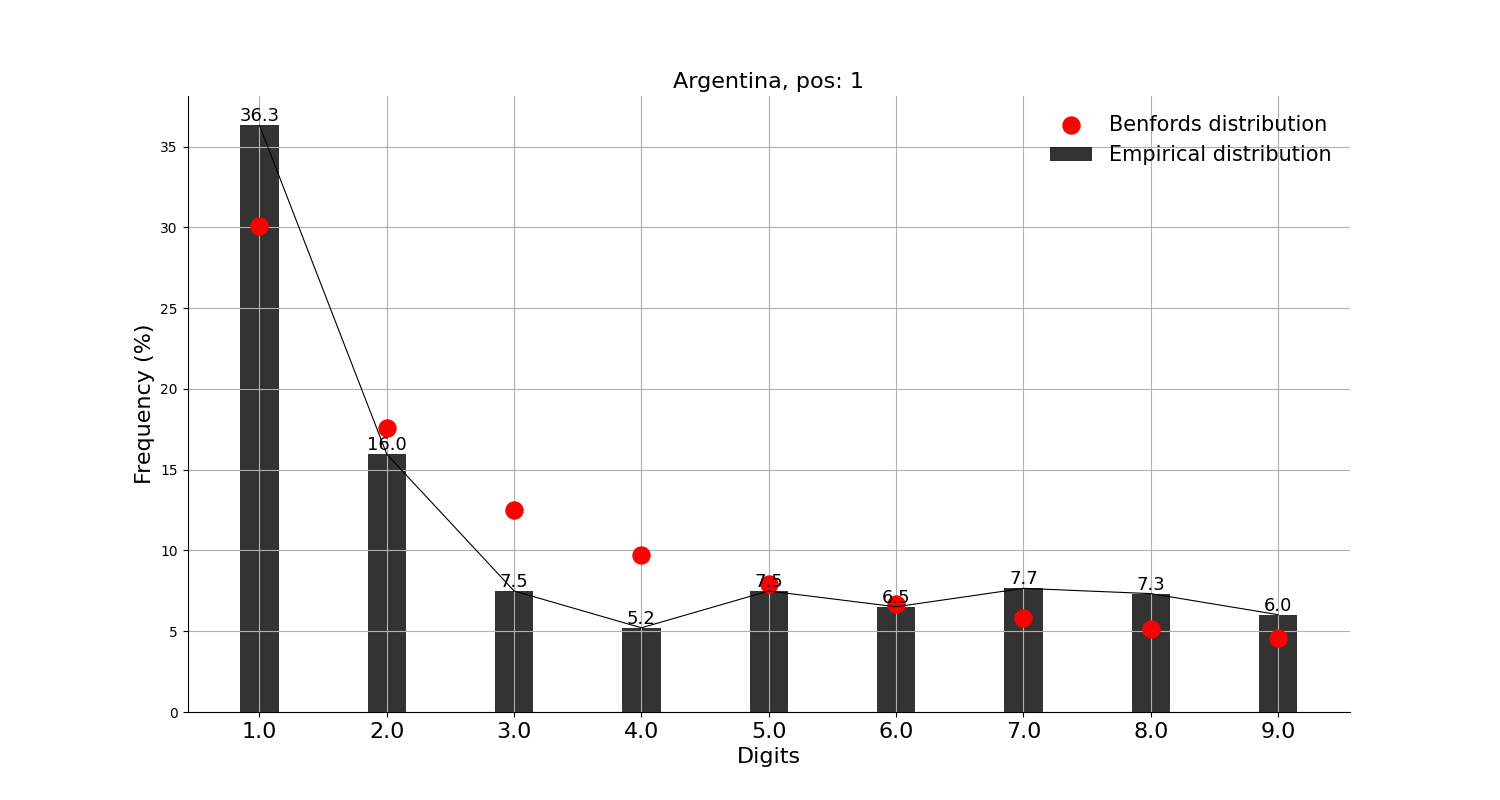
그리고, 확진자수 상위 10개국에는 안 들어가지만 독자들이 가장 관심 있을 중국, 일본과 우리나라에 적용해본 결과,
많은 의심을 받고 있는 중국을 포함한 세 나라 모두 벤포드 법칙에 크게 어긋나지 않는 모습을 보인다.
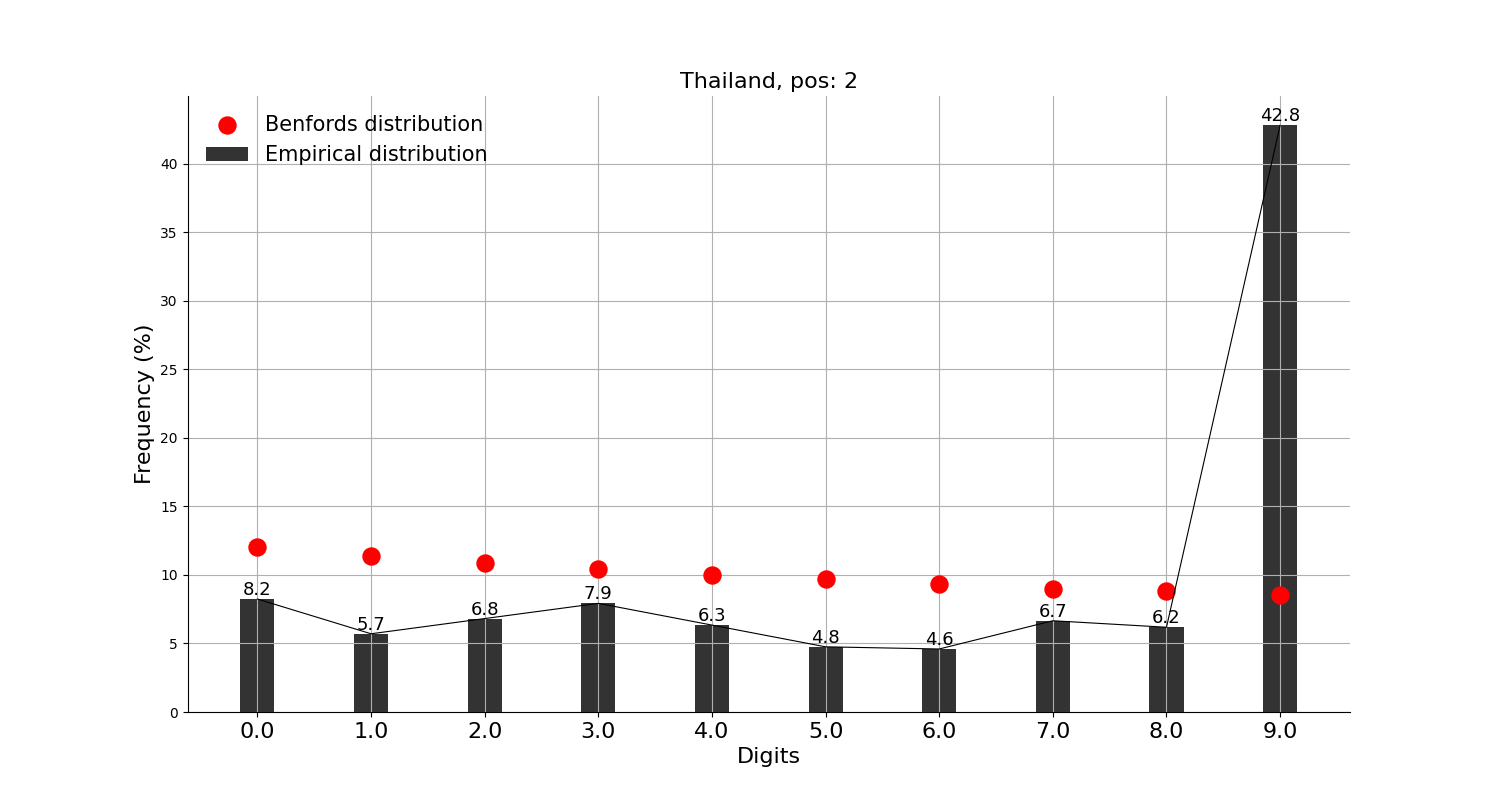
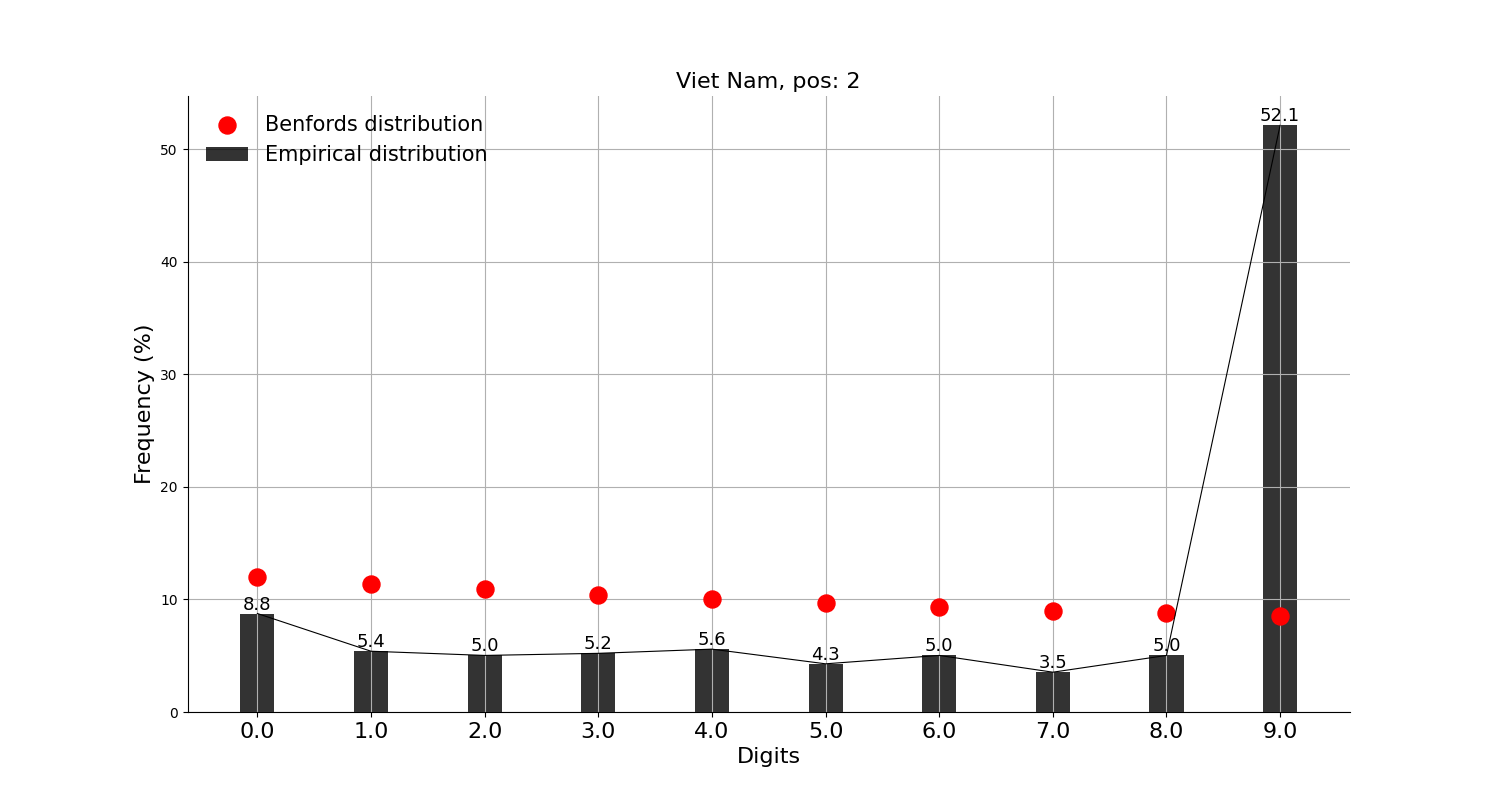
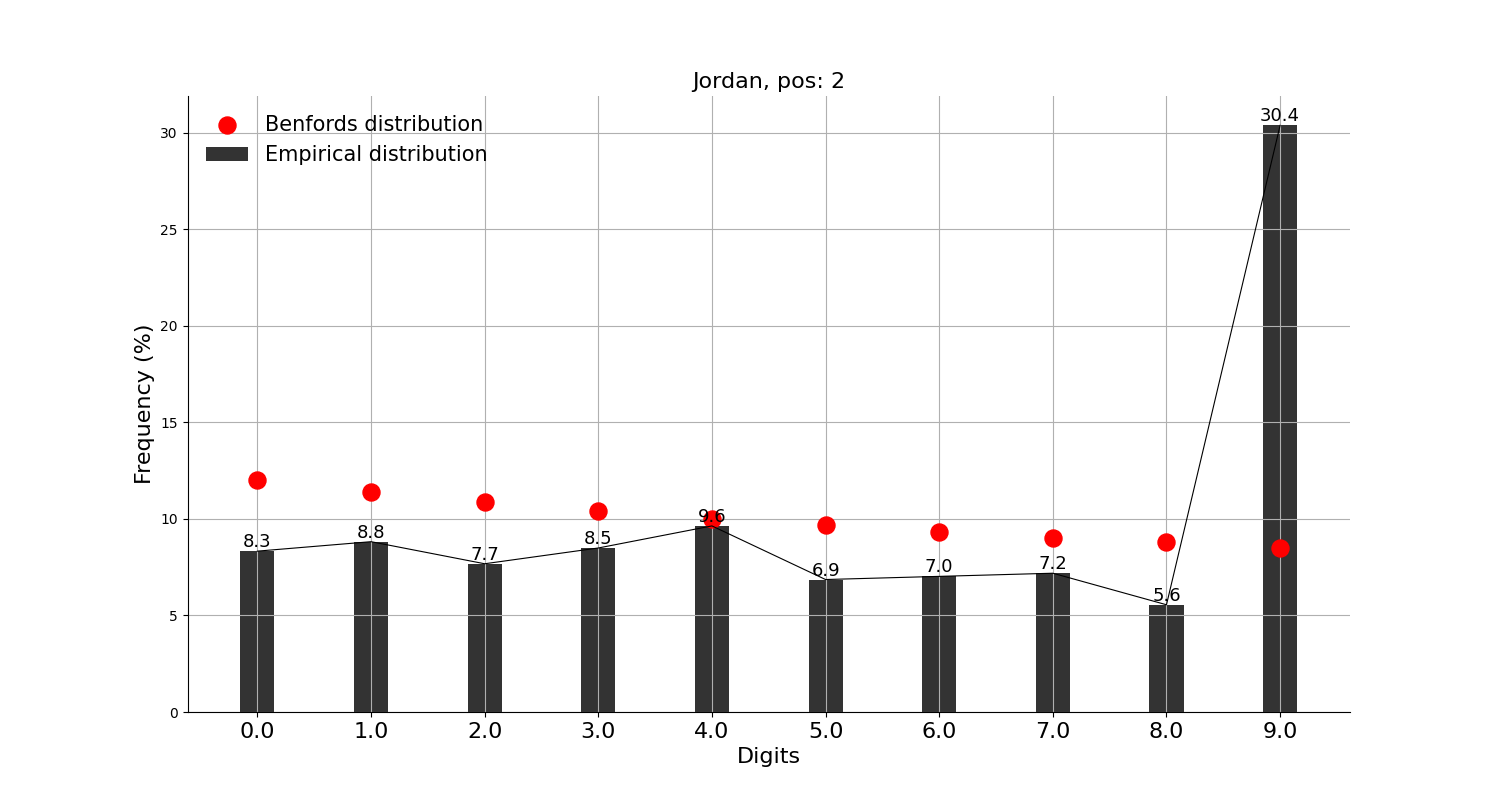
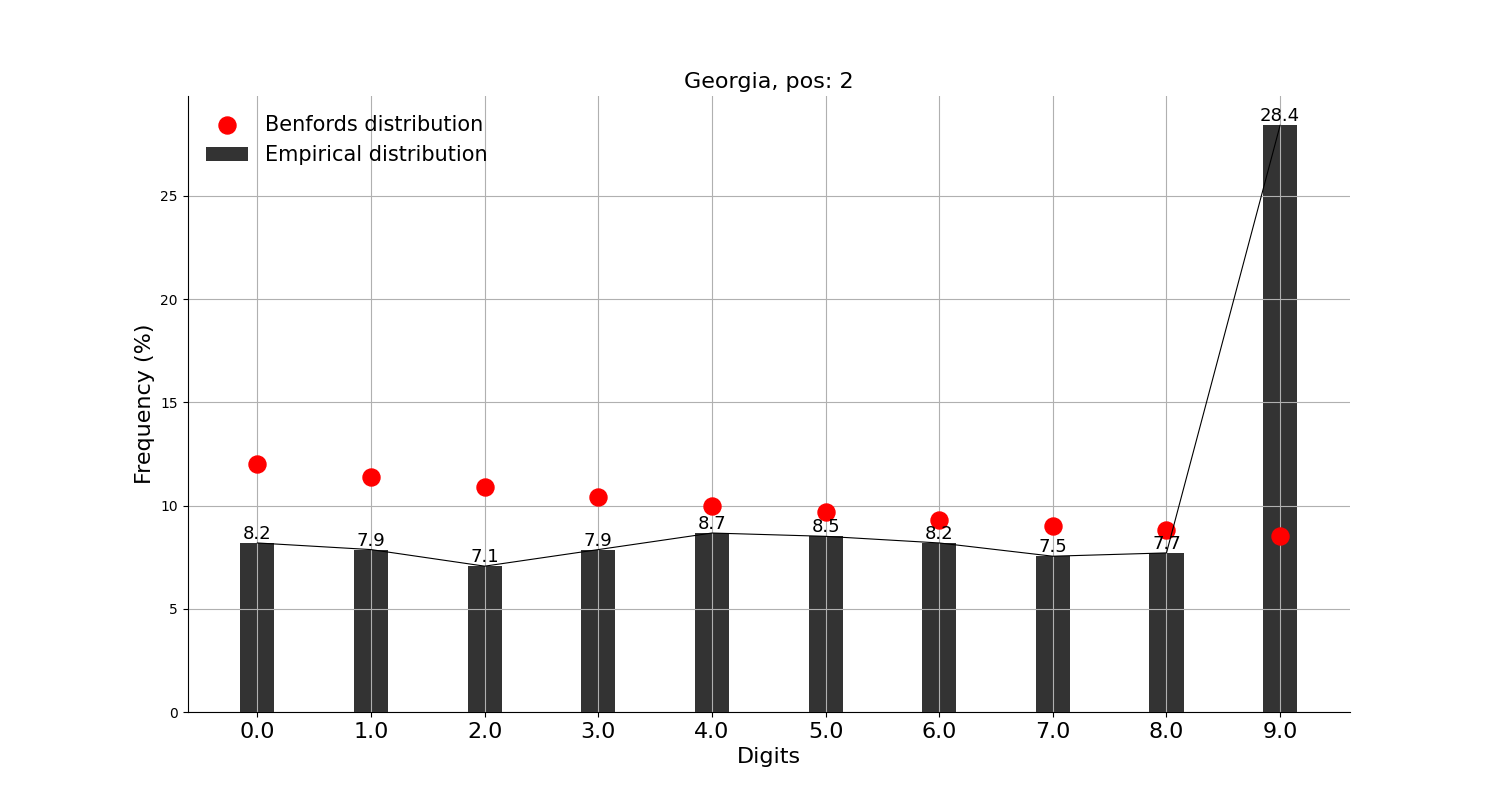
한편, 두번째 자리의 분석 결과를 보면
첫번째 자리보다는 벤포드 법칙이 잘 맞지 않아 보여 상위 10개국 분석 결과는 생략하고, 상위 50개국으로 확대하여 눈에 띄는 국가만 추려보았는데, 태국, 베트남, 요르단, 조지아 등 몇몇 국가들의 경우 9가 유난히 많다.
특히 베트남의 경우 둘째 자리가 9인 경우가 52%나 되는데, 예단해서는 안 되겠지만, 10,000원 짜리를 9,900원에 파는 것과 비슷한 이유가 있지 않을까 상상해볼 수는 있겠다.
최근의 기사를 보면 의도적인 것은 아니고 코로나 확진자 통계를 "누락"하였다가 다시 등록해서 일일 확진자 통계가 2만 8천명이 늘어났다고 하고 있는 점이 흥미롭다.
마무리
본문에서도 여러 차례 언급했지만, 벤포드 분석 결과만 보고 섣불리 어떠한 결론도 내려서는 안될 것이다.
재미로만 보도록 하자.
'코딩 > 데이터분석(Pandas, ML, etc)' 카테고리의 다른 글
| 판다스, 데이터 분석 책 추천/파이썬으로 데이터 주무르기 (0) | 2021.12.08 |
|---|---|
| 엑셀 대신 파이썬의 판다스 라이브러리를 사용해야 하는 이유 (0) | 2021.12.07 |
| 판다스(Pandas)에서 엑셀, CSV 파일 불러오기 기초 (0) | 2021.11.20 |
| 판다스(Pandas) 교재 추천, 책 추천/파이썬 라이브러리를 활용한 데이터 분석 (0) | 2021.11.20 |
| 판다스(Pandas) 주요 함수(명령어) 모음(정리표, cheat sheet) (0) | 2021.11.16 |




댓글